1. 变量和常量
首先希望学习 Go 语言的爱好者至少拥有其他语言的编程经验,如果是完全零基础的小白用户,本教程可能并不适合阅读或尝试阅读看看,系列笔记的目标是站在其他语言的角度学习新的语言,理解 Go 语言,进而写出真正的 Go 程序.
编程语言中一般都有变量和常量的概念,对于学习新语言也是一样,变量指的是不同编程语言的特殊之处,而常量就是编程语言的共同点.
学习 Go 语言时尽可能站在宏观角度上分析变量,而常量可能一笑而过或者编程语言不够丰富,所谓的常量其实也是变量,不管怎么样现在让我们开始 Go 语言的学习之旅吧,本教程涉及到的源码已托管于 github,如需获取源码,请直接访问 https://github.com/snowdreams1006/learn-go

1.1. 编写第一个 Hello World 程序
学习编程语言的第一件事就是编写出 Hello World,现在让我们用 Go 语言开发出第一个可运行的命令行程序吧!
环境前提准备可以参考 走进Goland编辑器
新建 main 目录,并新建 hello_world.go 文件,其中文件类型选择 Simple Application ,编辑器会帮助我们创建 Go 程序骨架.
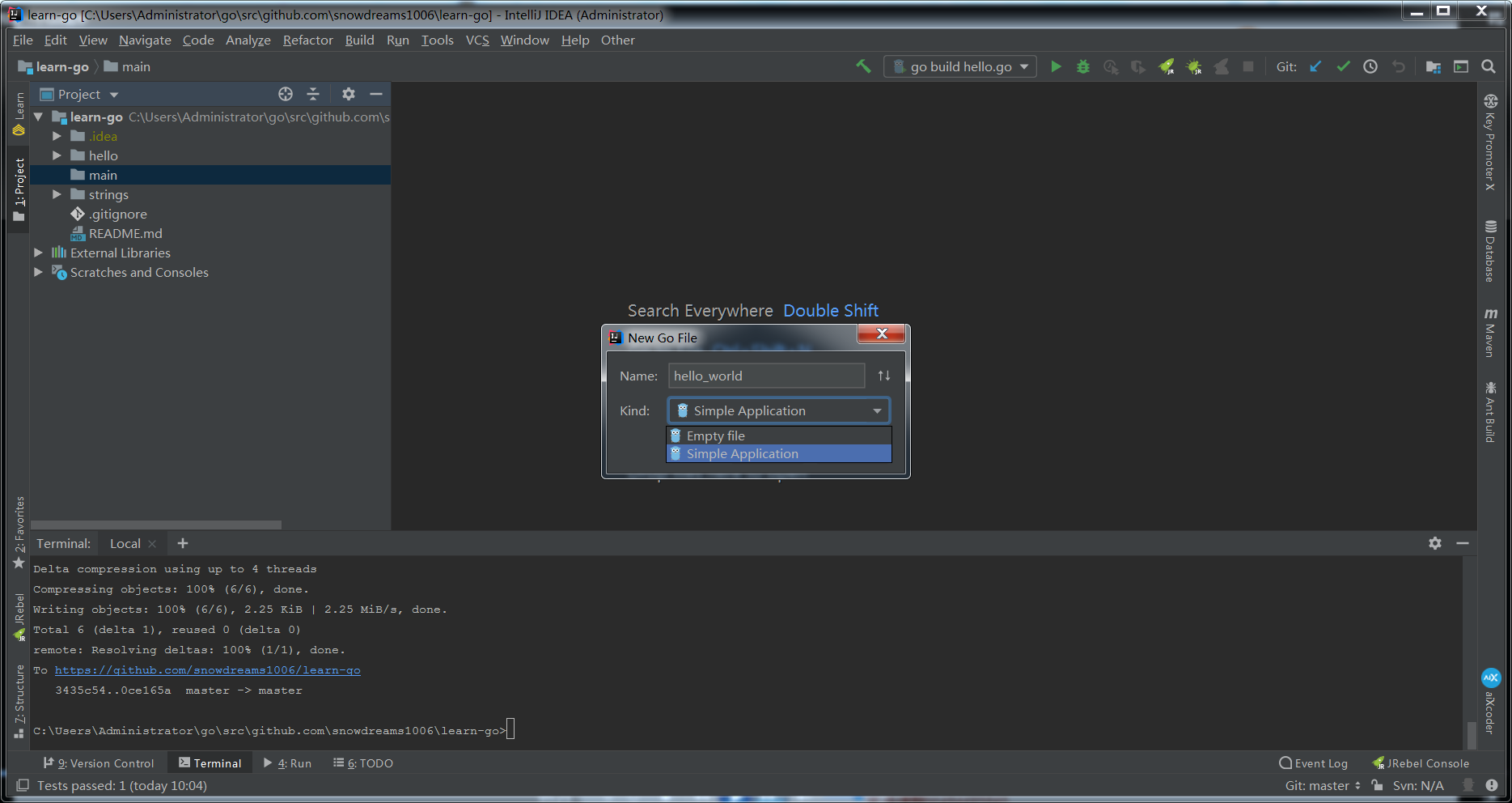
首先输入 fmt 后触发语法提示选择 fmt.Println ,然后会自动导入 fmt 包.
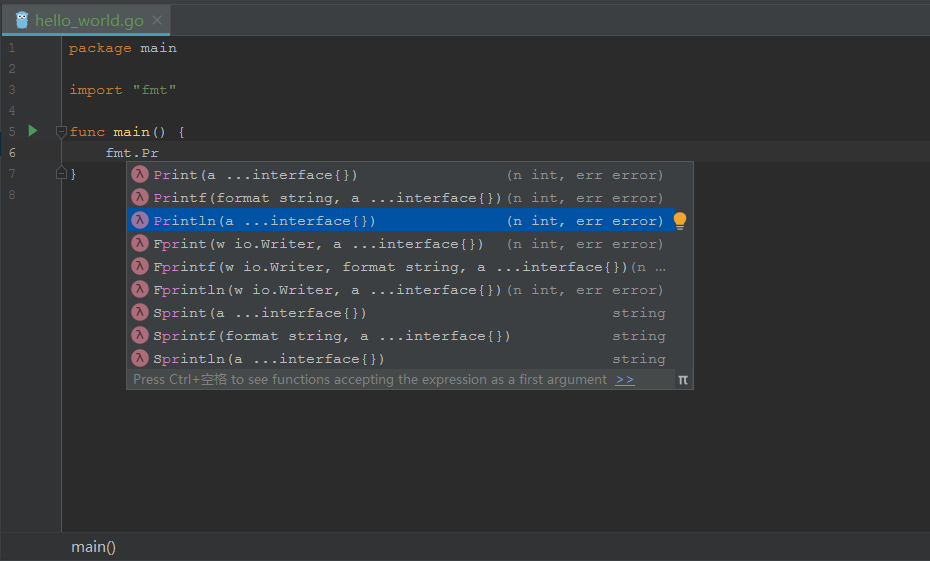
完整内容如下,仅供参考:
package main
import "fmt"
func main() {
fmt.Println("Hello World")
}
点击左侧绿色启动按钮,可以直接运行程序或者利用程序自带的 Terminal 终端选项卡运行程序,当然也可以用外部命令行工具运行程序.
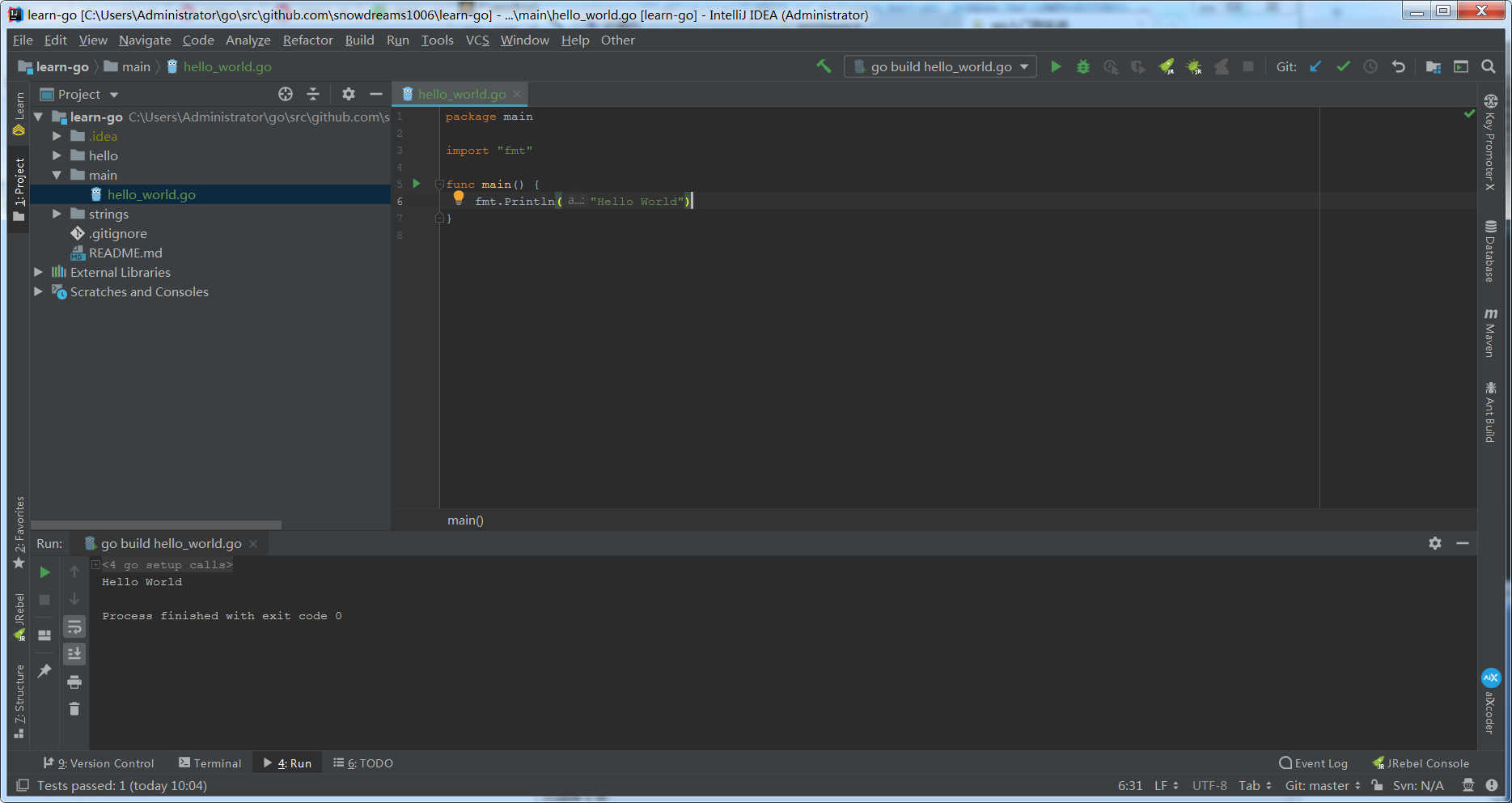
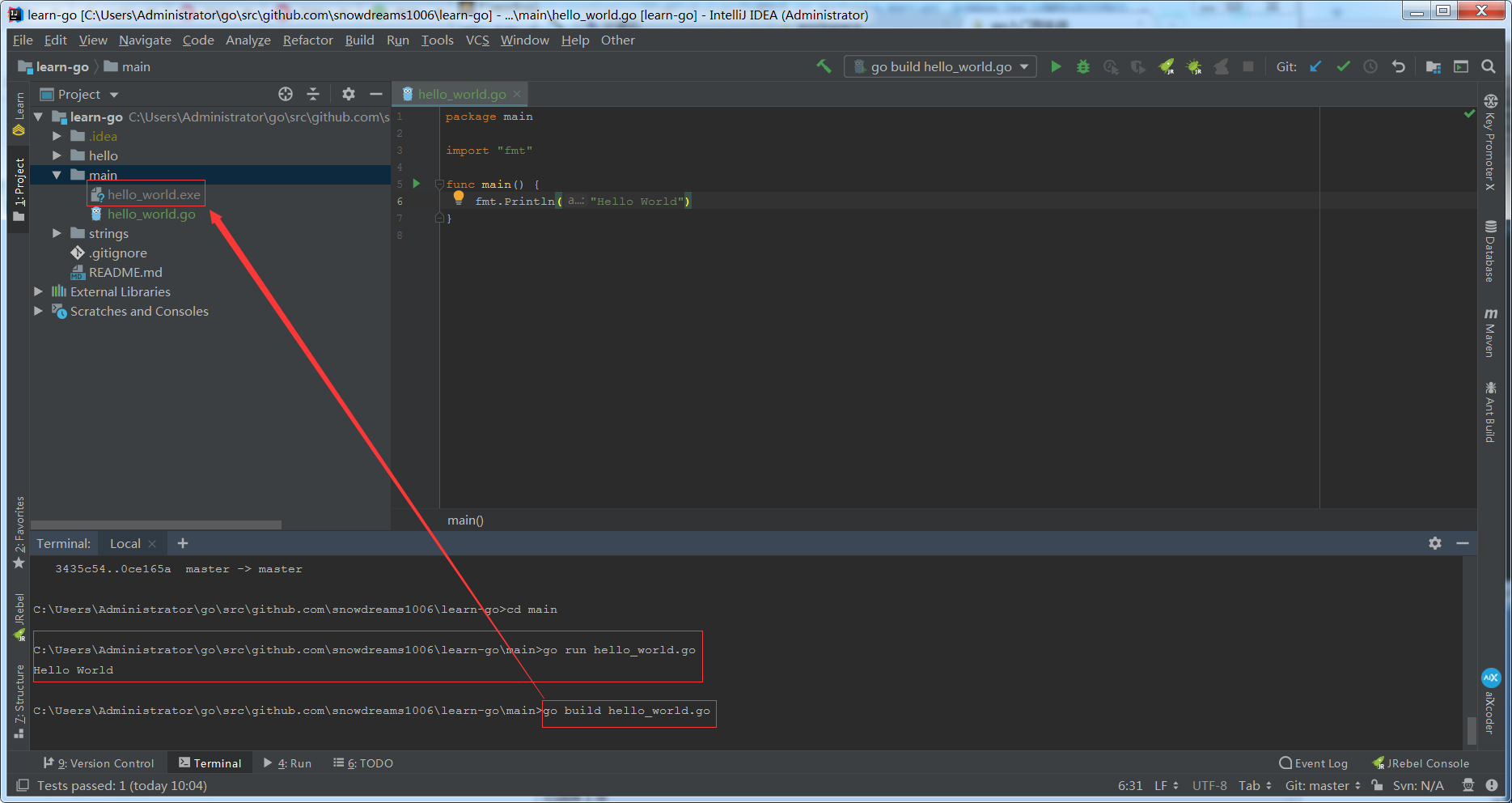
go run 命令直接运行,而 go build 命令产生可执行文件,两种方式都能如愿以偿输出 Hello World .
1.1.1. 知识点归纳
Go 应用程序入口的有以下要求:
- 必须是
main包 :package main - 必须是
main方法 :func main() - 文件名任意不一定是
main.go,目录名也任意不一定是main目录.
以上规则可以很容易在编辑器中得到验证,任意一条不符合规则,程序都会报错提示,这也是使用编辑器而不是命令行进行学习的原因,能够帮助我们及时发现错误,方便随时验证猜想.
总结来说,main 包不一定在 main 目录下,main 方法可以在任意文件中.
这也意味着程序入口所在的目录不一定叫做 main 目录却一定要声明为 main 包,虽然不理解为什么这么设计,这一点至少和 Java 完全不一样,至少意味着 Go文件可以直接迁移目录而不需要语言层面的重构,可能有点方面,同时也有点疑惑?!

main 函数值得注意的不同之处:
main函数不支持返回值,但可以通过os.Exit返回退出状态
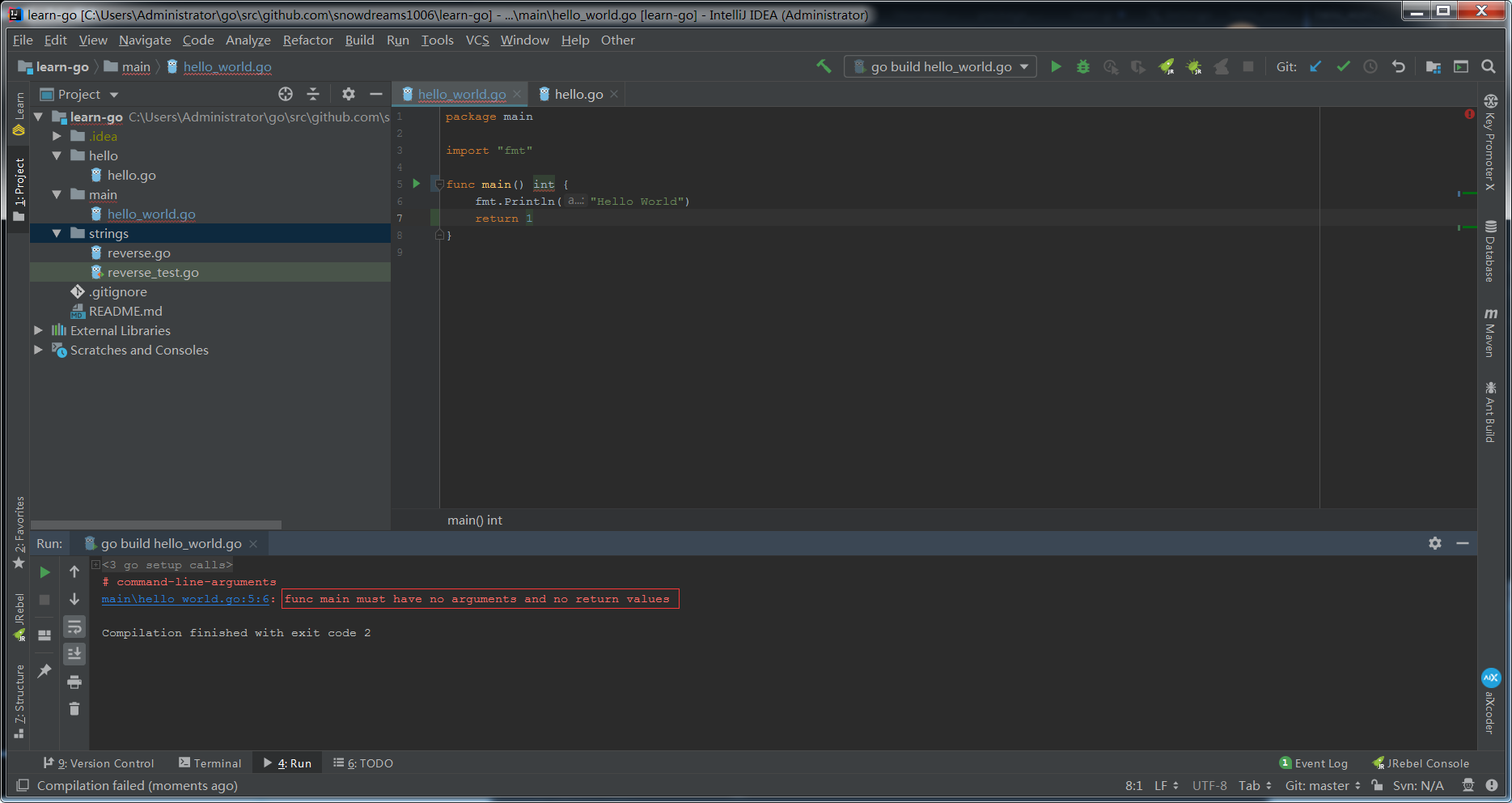
main函数,不支持返回值,若此时强行运行main方法,则会报错:func main must have no arguments and no return values
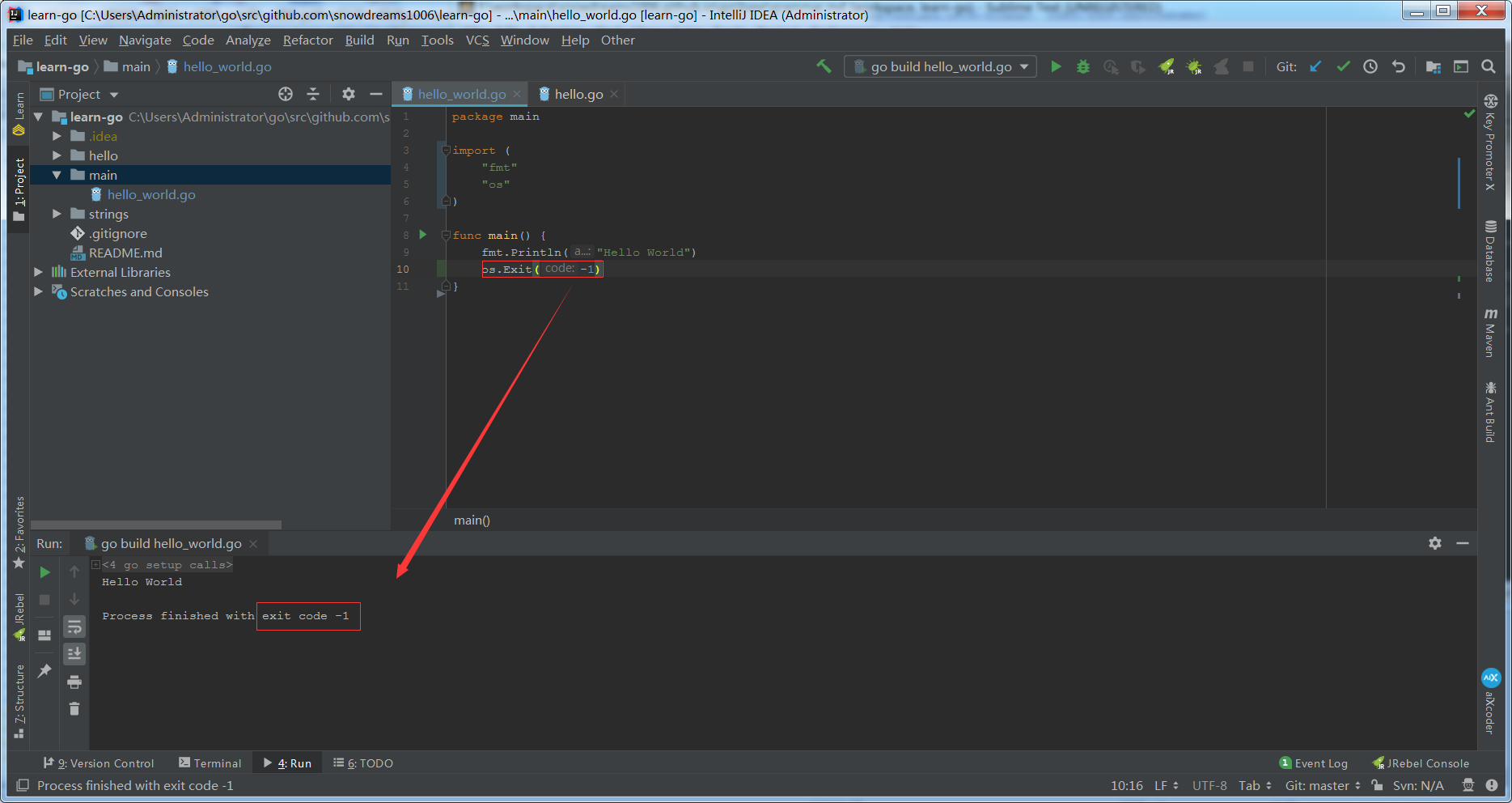
main函数可以借助os.Exit(-1)返回程序退出时状态码,外界可以根据不同状态码识别相应状态.
main函数不支持传入参数,但可以通过os.Args获取参数
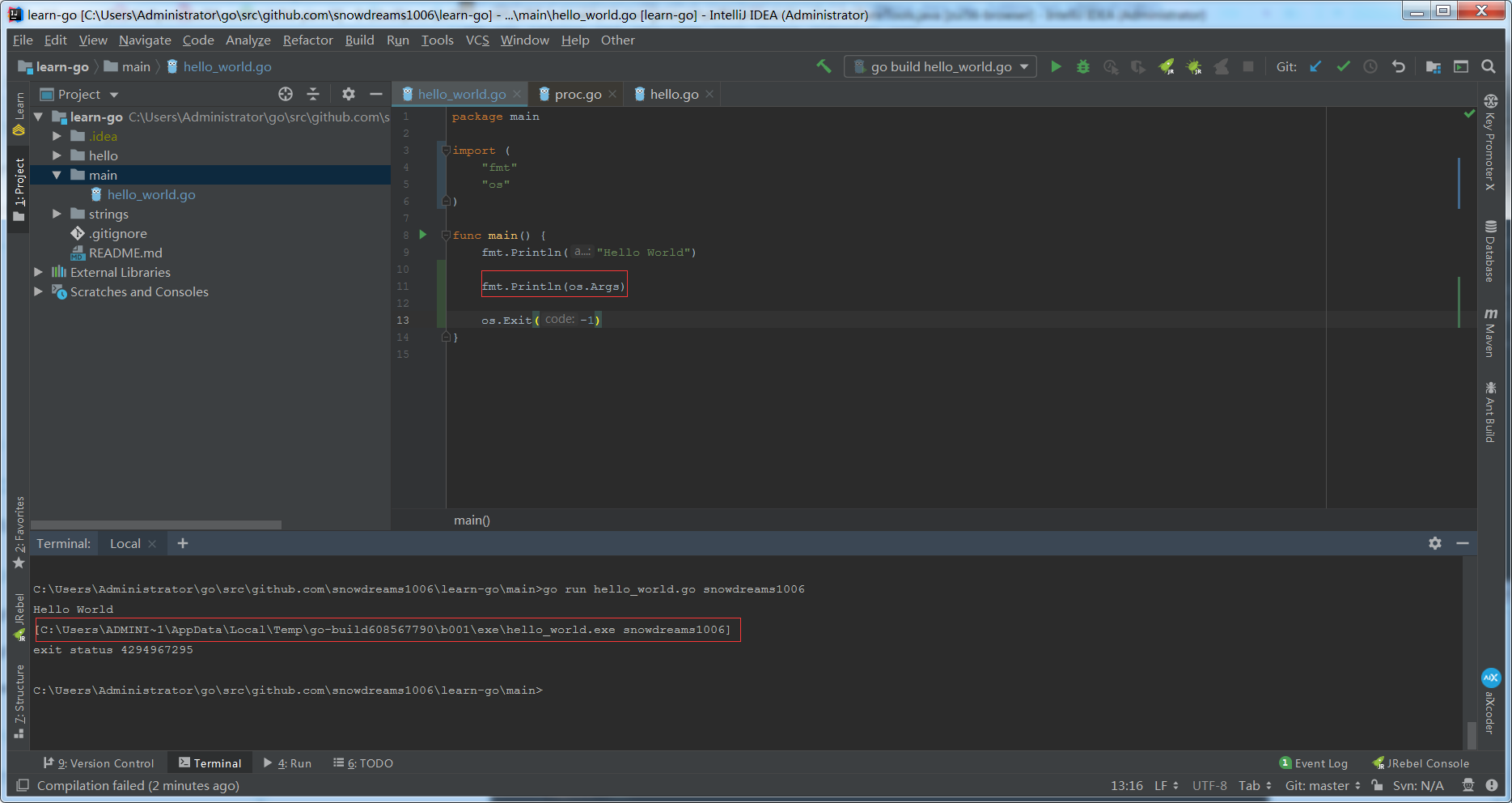
在
Terminal终端选项卡中运行go run hello_world.go snowdreams1006命令os.Args输出命令路径和参数值.
1.2. 在测试用例中边学边练基础语法
The master has failed more times than the beginner has tried
计算机编程不是理科而是工科,动手亲自实践一遍才能更好地掌握知识技能,幸运的是,Go 语言本身内置提供了测试框架,不用加载第三方类库扩展,非常有利于学习练习.
刚刚接触 Go 语言,暂时不需要深入讲解如何编写规范的测试程序,毕竟基础语法还没开始正式练习呢!
但是,简单的规则还是要说的,总体来说,只有两条规则:
- 测试文件名以
_test结尾 :XXX_test.go
命令习惯和不同,
Java中的文件名一般是大驼峰命名法,相应的测试文件是XXXTest
- 测试方法名以
Test开头 :TestXXX
命名习惯和其他编程语言不同,
Java中的测试方法命名是一般是小驼峰命名法,相应的测试方法是testXXX
- 测试方法有着固定的参数 :
t *testing.T
其他编程语言中一般没有参数,
Java中的测试方法一定没有参数,否则抛出异常java.lang.Exception: Method testXXX should have no parameters
新建 Go 文件,类型选择 Empty File ,文件名命名为 hello_world_test ,编辑器新建一个空白的测试文件.
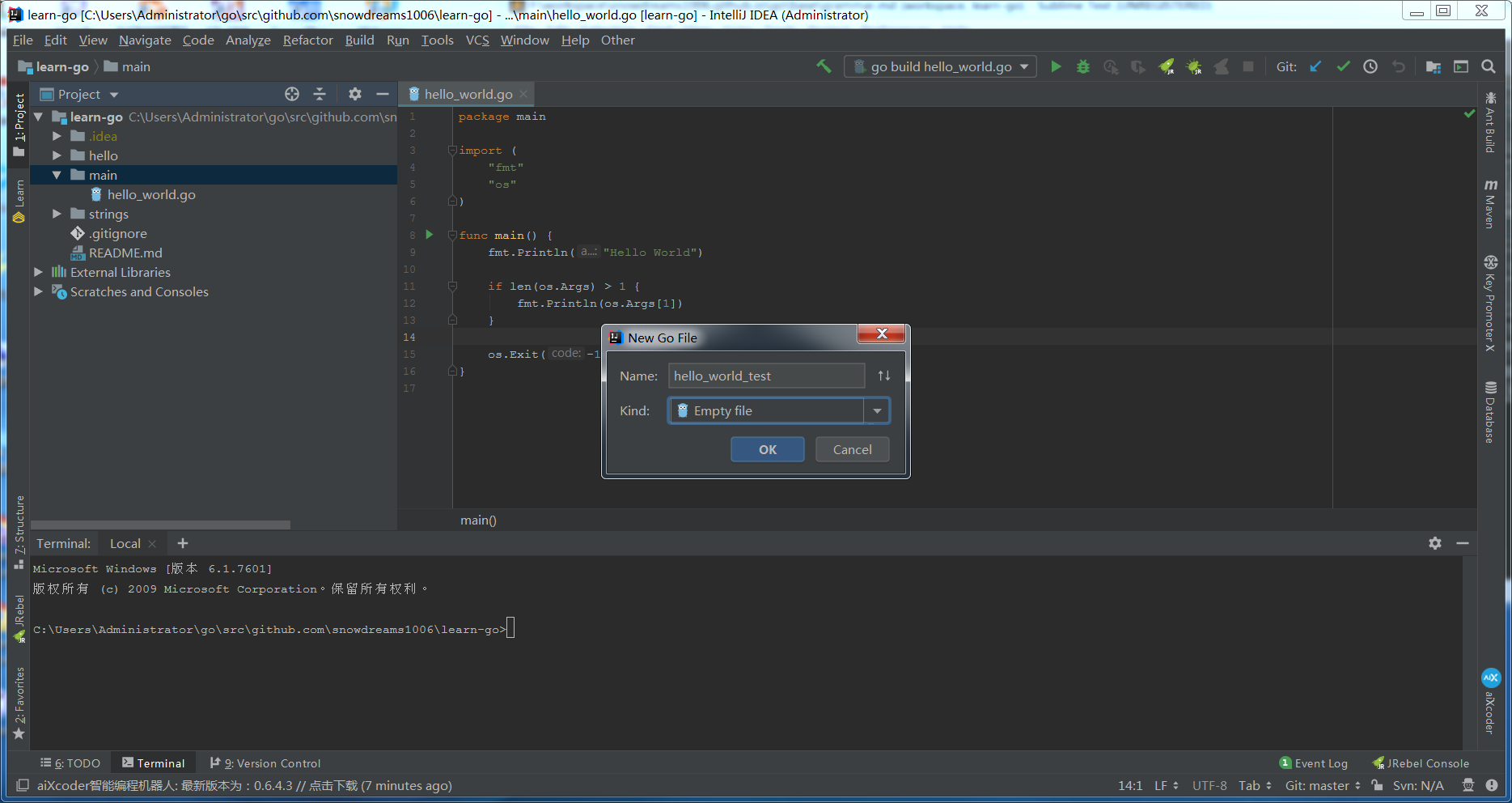
此时编写测试方法签名,利用编辑器自动提示功能输入 t.Log 随便输出些内容,这样就完成了第一个测试文件.
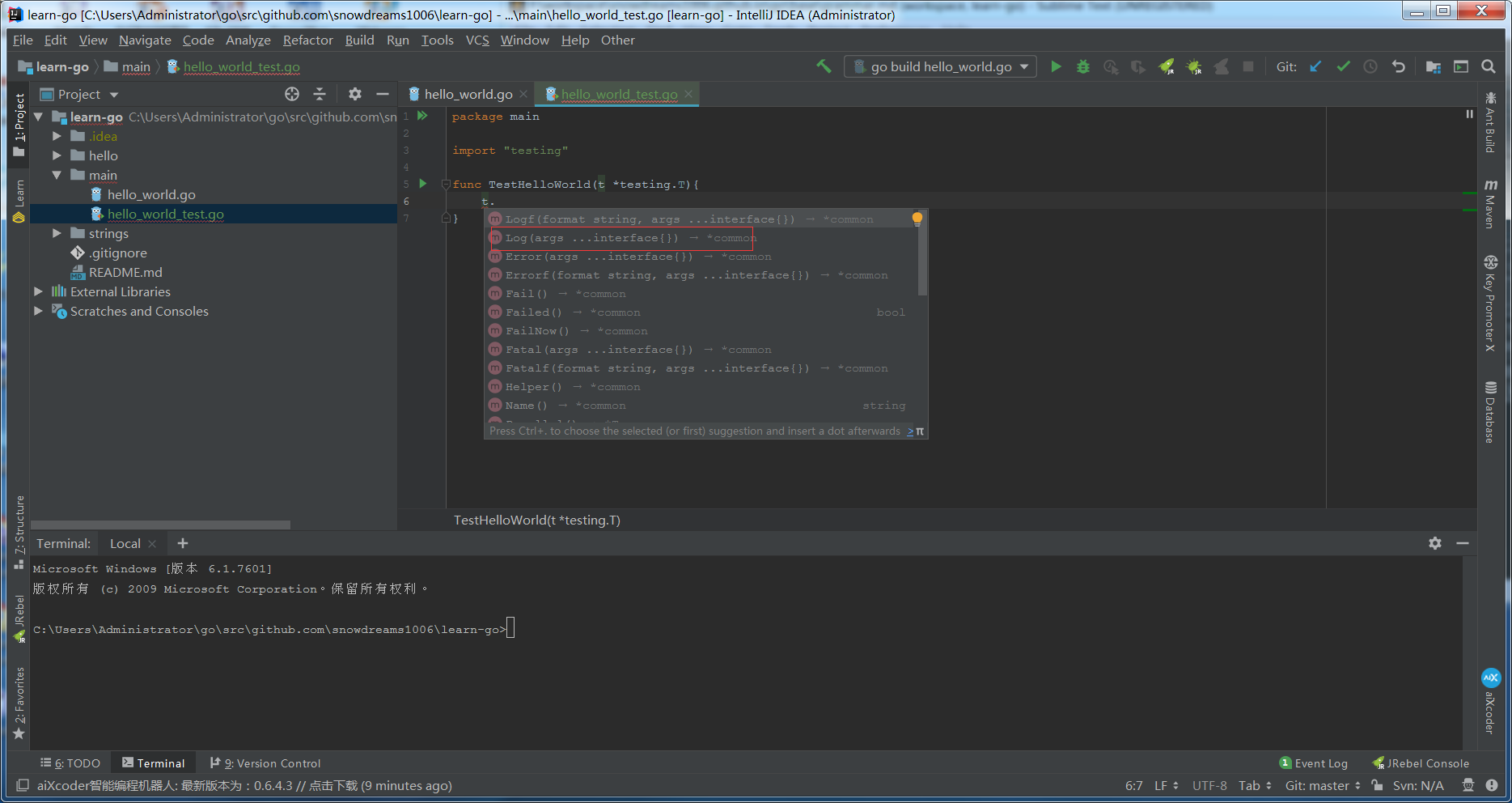
和 main 程序一样,测试方法也是可执行的,编辑器窗口的左侧也会出现绿色启动按钮,运行测试用例在编辑器下方的控制台窗口输出 PASS 证明测试逻辑正确!
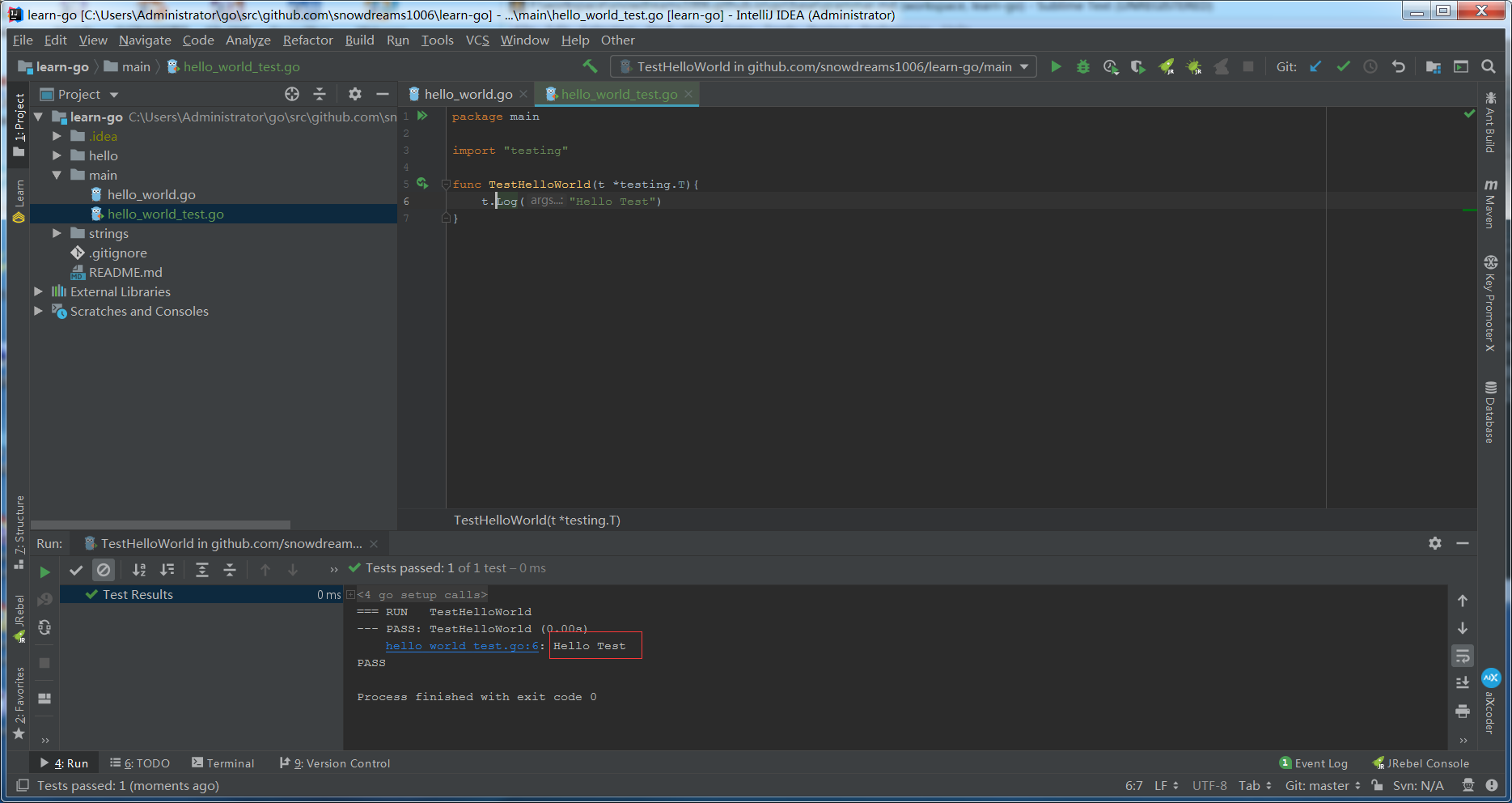
测试文件源码示例:
package main
import "testing"
func TestHelloWorld(t *testing.T){
t.Log("Hello Test")
}
现在已经学习了两种基本方式,一种是把程序写在 main 方法中,另一种是把程序写在测试方法中.
两种方式都可以随时测试验证我们的学习成果,如果写在 main 方法中,知识点一般要包装成单独的方法,然后再在 main 方法中运行该方法.
如果写在测试方法中,可以单独运行测试方法,而不必在 main 方法中一次性全部运行.
当然,这两种方式都可以,只不过个人倾向于测试用例方式.
1.2.1. 实现 Fibonacci 数列
形如 1,1,2,3,5,8,13,... 形式的数列就是斐波那契数列,特点是从三个元素开始,下一个元素的值就是前两两个元素值的总和,子子孙孙无穷尽也!
记得学习初中历史时,关于昭君出塞的故事广为人知,王昭君的美貌不是此次讨论的重点,而此次关注点是放到了昭君的悲惨人生.
汉朝和匈奴和亲以换取边境和平,汉朝皇帝不愿意自己的亲闺女远嫁塞北,于是从后宫中挑选了一名普通宫女充当和亲对象,谁成想这名宫女竟长得如此美貌,"沉鱼落雁闭月羞花",堪称古代中国四大美女之一!
昭君担负着和亲重任,从此开始了远离他乡的悲惨生活,一路上,黄沙飞扬,燥热忧伤,情之所至,昭君拿出随性的琵琶,演奏出感人泪下的<<琵琶怨>>!
"千载琵琶作胡语,分明怨恨曲中论",可能情感过于哀伤,竟然连天上的大雁都忘记了飞翔,因此收获落雁之美!

老单于这个肥波纳了个如花似玉的妾,做梦都能了醒吧,遗憾的是,命不久矣!
如此一来,昭君却满心欢喜,异族老公死了,使命完成了,应该能回到朝思梦想的大汉朝故土了吧?
命运弄人,匈奴文化,父死子继,肥波已逝,但还有小肥波啊,放到汉朝伦理纲常来看,都不能叫做近亲结婚了简直是乱伦好吗!
小肥波+昭君=小小肥波 ,只要昭君不死,而昭君的现任老公不幸先死,那么小小肥波又会继续纳妾生娃,理论上真的是子子孙孙无穷尽也!
肥波纳妾故事可能长成这个样子:
肥波,昭君,小肥波
昭君的第一任老公:
肥波+昭君=小肥波,此时昭君刚生一个娃
肥波,小肥波,昭君,小小肥波
昭君的第二任老公:
小肥波+昭君=小小肥波,昭君的娃娶了自己的妈?难怪昭君苦楚悲惨,有苦难言,幸运的是,这次昭君没有生娃,两个女孩!
肥波,小肥波,小小肥波,昭君
昭君的第三任老公,
小小肥波+昭君=小小小肥波,兄终弟及,还是乱伦好吗,这辈分我是算不出来了.
肥波纳妾系列,理论上和愚公移山有的一拼,生命不息,子承父业也好,兄终弟及也罢,数量越来越多,肚子越来越大.
以上故事,纯属虚构,昭君出塞是一件伟大的事情,换来了百年和平,值得尊敬.
回归正题,下面让我们用 Go 语言实现斐波那契数列吧!
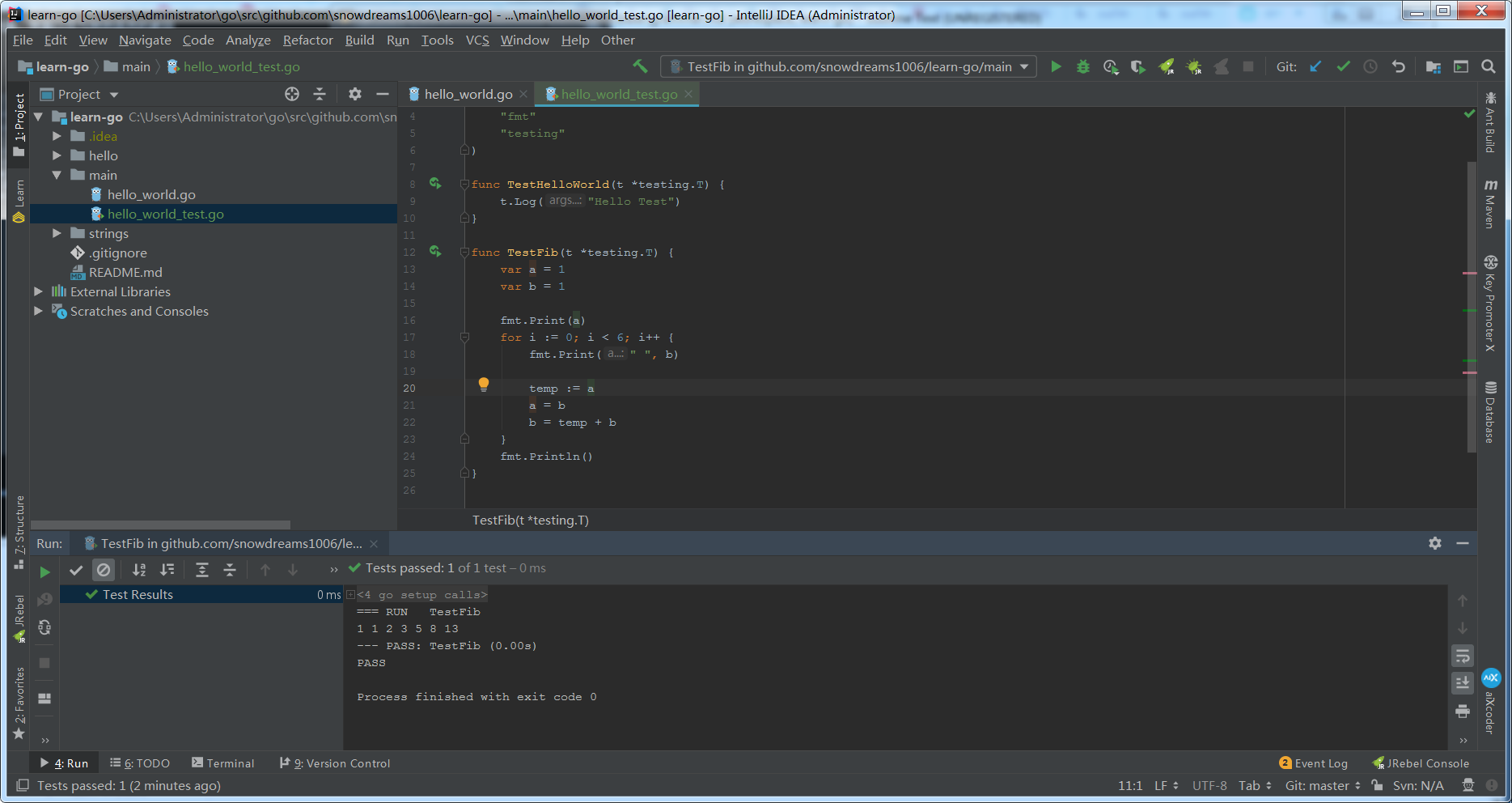
func TestFib(t *testing.T) {
var a = 1
var b = 1
fmt.Print(a)
for i := 0; i < 6; i++ {
fmt.Print(" ", b)
temp := a
a = b
b = temp + b
}
fmt.Println()
}
上述简单示例,展示了变量的基本使用,简单总结如下:
- 变量声明关键字用
var,类型名在前,变量类型在后,其中变量类型可以省略.
// 声明变量a和变量b
var a = 1
var b = 1
上述变量语法咋一看像是 Js 赋值,严格来说其实并不是那样,上面变量赋值形式只是下面这种的简化
// 声明变量a并指定类型为 int,同理声明变量b并指定类型为int
var a int = 1
var b int = 1
第一种写法省略了 int 类型,由赋值 1 自动推断为 int 在一定程度上简化了书写,当然这种形式还可以继续简化.
// 省略相同的 var,增加一对小括号 (),将变量放到小括号里面
var (
a = 1
b = 1
)
可能问,还能不能继续简化下,毕竟其余语言的简化形式可不是那样的,答案是可以的!
// 连续声明变量并赋值
var a, b = 1, 1
当然,其余语言也有类似的写法,这并不值得骄傲,下面这种形式才是 Go 语言特有的精简版形式.
// 省略了关键字var,赋值符号=改成了:=,表示声明变量并赋值
a, b := 1, 1
就问你服不服?一个小小的变量赋值都能玩出五种花样,厉害了,我的 Go !
- 变量类型可以省略,由编译器自动进行类型推断
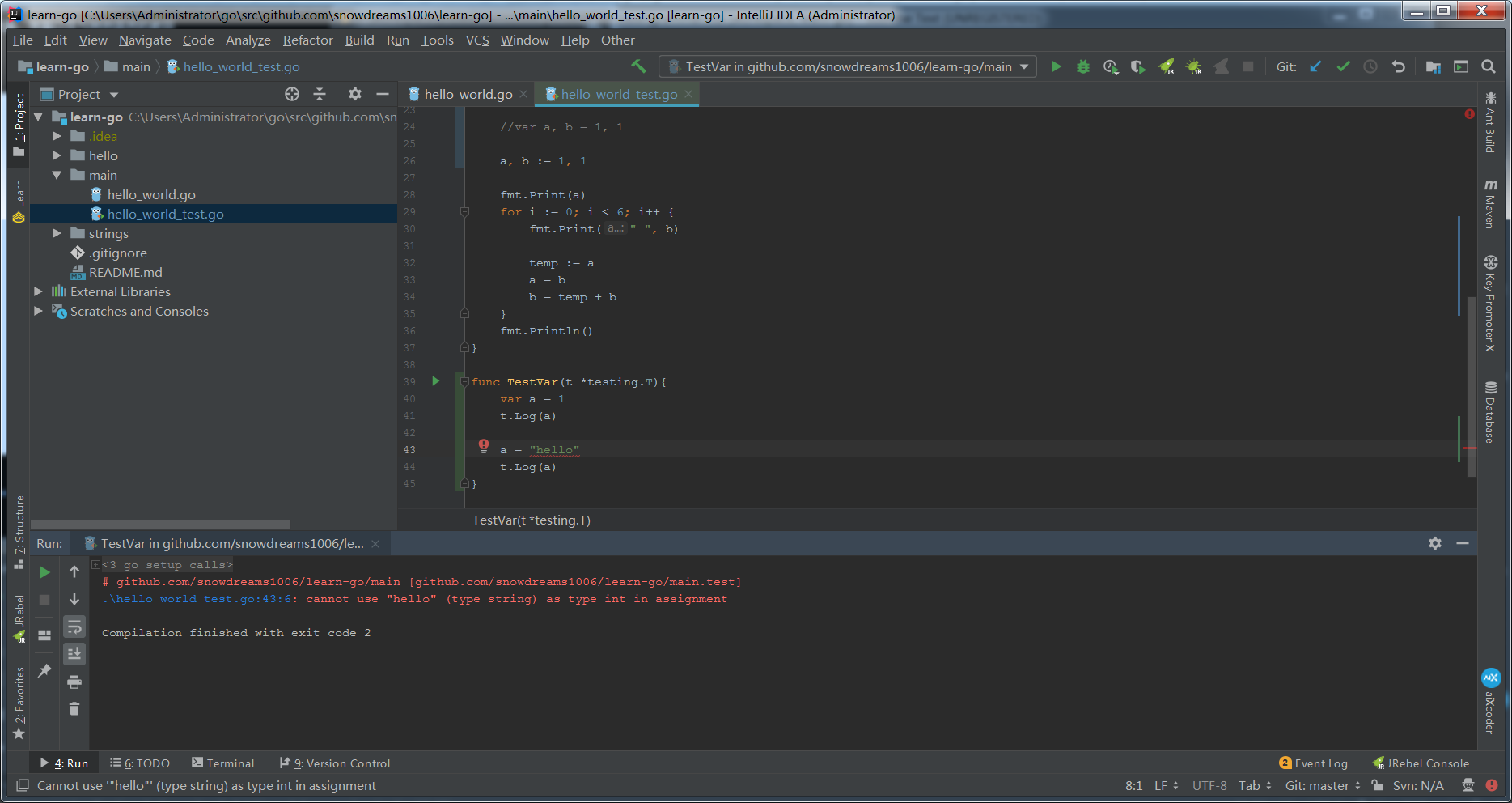
类似
Js的书写习惯,但本质上仍然是强类型,不会进行不同类型的自动转换,还会说像Js的变量吗?
- 同一个变量语句可以对不同变量进行同时赋值
仍然以斐波那契数列为例,Go 官网的示例中使用到的就是变量同时赋值的特性,完整代码如下:
package main
import "fmt"
// fib returns a function that returns
// successive Fibonacci numbers.
func fib() func() int {
a, b := 0, 1
return func() int {
a, b = b, a+b
return a
}
}
func main() {
f := fib()
// Function calls are evaluated left-to-right.
fmt.Println(f(), f(), f(), f(), f())
}
如果对该特性认识不够清晰,可能觉得这并不是什么大不了的事情嘛!
实际上,俗话说,没有对比就没有伤害,举一个简单的例子: 交换变量
func TestExchange(t *testing.T) {
a, b := 1, 2
t.Log(a,b)
a, b = b, a
t.Log(a,b)
temp := a
a = b
b = temp
t.Log(a,b)
}
其他语言中如果需要交换两个变量,一般都是引入第三个临时变量的写法,而 Go 实现变量交换则非常简单清晰,也符合人的思考而不是计算机的思考.
虽然不清楚底层会不会仍然是采用临时变量交换,但不管怎么说,使用该特性交换变量确实很方便!
同时对多个变量进行赋值是
Go特有的语法,其他语言可以同时声明多个变量但不能同时赋值.
- 常量同样很有意思,也有关键字声明
const.
有些编程语言对常量和变量没有强制规定,常量可以逻辑上被视为不会修改的变量,一般用全大写字母提示用户是常量,为了防止常量被修改,有的编程语言可能会有额外的关键字进行约束.
幸运的是,Go 语言的常量提供了关键字 const 约束,并且禁止重复赋值,这一点很好,简单方便.
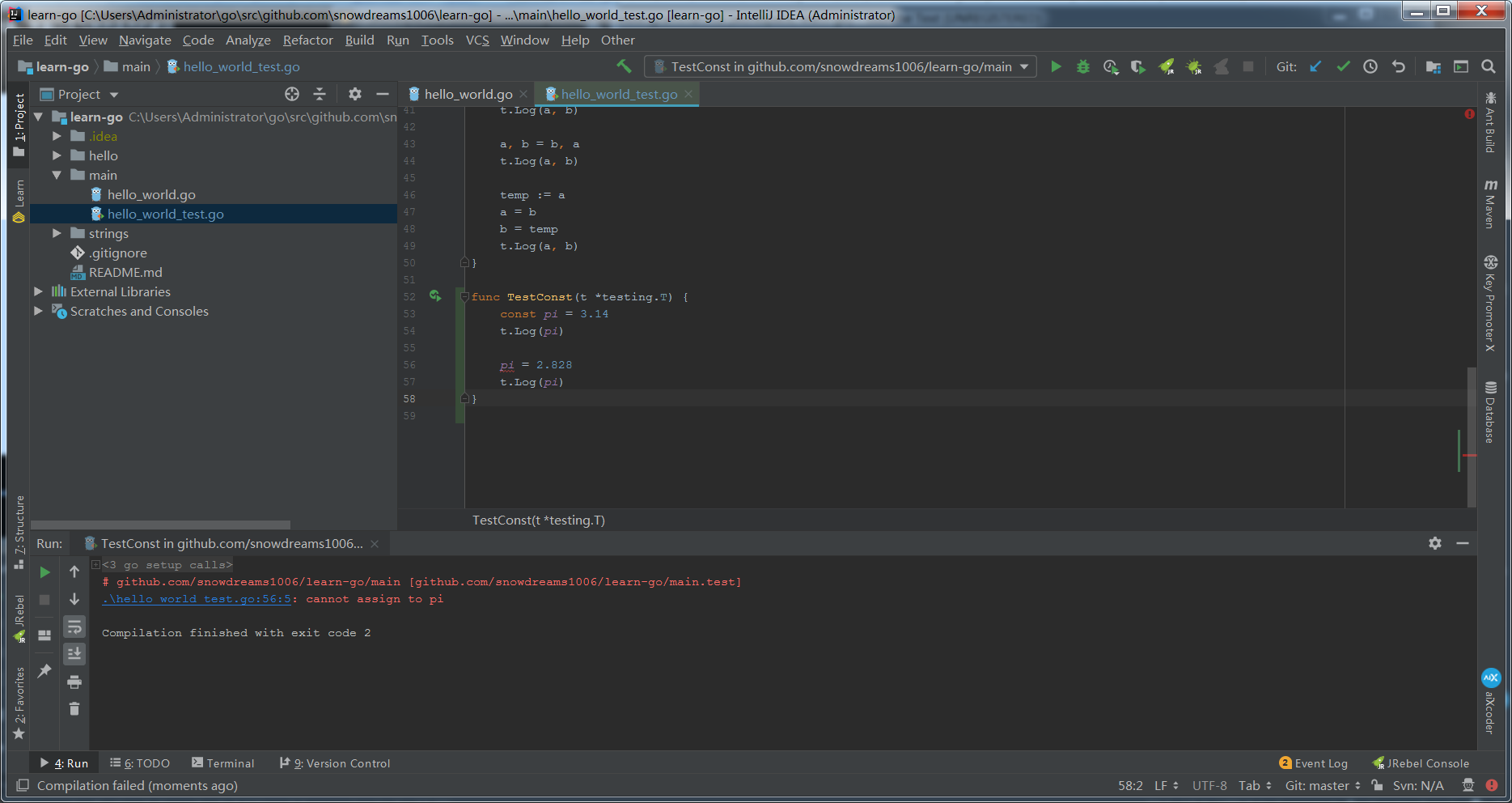
func TestConst(t *testing.T) {
const pi = 3.14
t.Log(pi)
// cannot assign to pi
pi = 2.828
t.Log(pi)
}
除了语言层面的 const 常量关键字,Go 语言还要一个特殊的关键字 iota ,常常和常量一起搭配使用!
当设置一些连续常量值或者有一定规律的常量值时,iota 可以帮助我们快速设置.
func TestConstForIota(t *testing.T) {
const (
Mon = 1 + iota
Tue
Wed
Thu
Fri
Sat
Sun
)
// 1 2 3 4 5 6 7
t.Log(Mon, Tue, Wed, Thu, Fri, Sat, Sun)
}
大多数编程语言中,星期一代表的数字几乎都是 0,星期二是 1,以此类推,导致和传统认识上偏差,为了校准偏差,更加符合国人习惯,因此将星期一代表的数字 0 加一,以此类推,设置初始 iota 后就可以剩余星期应用该规律,依次 1,2,3,4,5,6,7
如果不使用 iota 的话,可能需要手动进行连续赋值,比较繁琐,引入了 iota 除了帮助快速设置,还可以进行比特位级别的操作.
func TestConstForIota(t *testing.T) {
const (
Readable = 1 << iota
Writing
Executable
)
// 0001 0010 0100 即 1 2 4
t.Log(Readable, Writing, Executable)
}
第一位比特位为 1 时,表示文件可读,第二位比特位为 1 时,表示可写,第三位比特位为 1 时,表示可执行,相应的 10 进制数值依次为 1,2,4 也就是左移一位,左移两位,左移三位,数学上也可以记成 2^0,2^1,2^2 .
文件的可读,可写,可执行三种状态代表了文件的权限状态码,从而实现了文件的基本权限操作,常见的权限码有 755 和 644.
按位与 & 运算与编程语言无关,"两位同时为 1 时,按位与的结果才为 1 ,否则结果为 0 ",因此给定权限码我们可以很方便判断该权限是否拥有可读,可写,可执行等权限.
// 0111 即 7,表示可读,可写,可执行
accessCode := 7
t.Log(accessCode&Readable == Readable, accessCode&Writing == Writing, accessCode&Executable == Executable)
// 0110 即 6,表示不可读,可写,可执行
accessCode = 6
t.Log(accessCode&Readable == Readable, accessCode&Writing == Writing, accessCode&Executable == Executable)
// 0100 即 4,表示不可读,不可写,可执行
accessCode = 4
t.Log(accessCode&Readable == Readable, accessCode&Writing == Writing, accessCode&Executable == Executable)
// 0000 即 0,表示不可读,不可写,不可执行
accessCode = 0
t.Log(accessCode&Readable == Readable, accessCode&Writing == Writing, accessCode&Executable == Executable)
accessCode&Readable 表示目标权限码和可读权限码进行按位与运算,而可读权限码的二进制表示值为 0001 ,因此只要目标权限码的二进制表示值第一位是 1 ,按位与的结果肯定是 0001 ,而 0001 又刚好是可读权限码,所以 accessCode&Readable == Readable 为 true 就意味着目标权限码拥有可读权限.
如果目标权限码的二进制位第一个不是 1 而是 0,则 0&1=0 ,(0|1)^0=0,所以按位与运算结果肯定全是 0 即 0000,此时 0000 == 0001 比较值 false ,也就是该权限码不可读.
同理可自主分析,accessCode&Writing == Writing 结果 true 则意味着可写,否则不可写,accessCode&Executable == Executable 结果 true 意味着可执行,false 意味着不可执行.
熟悉了 iota 的数学计算和比特位计算后,我们趁热打铁,用文件大小单位继续练习!
func TestConstForIota(t *testing.T) {
const (
B = 1 << (10 * iota)
Kb
Mb
Gb
Tb
Pb
)
// 1 1024 1048576 1073741824 1099511627776 1125899906842624
t.Log(B, Kb, Mb, Gb, Tb, Pb)
// 62.9 KB (64,411 字节)
size := 64411.0
t.Log(size, size/Kb)
}
字节 Byte 与 千字节 Kilobyte 之间的进制单位是 1024 ,也就是 2^10 ,刚好可以用 iota 左移 10 位来表示,一次只移动一次,直接乘以 10 就好了!
怎么样,iota 是不是很神奇?同时是不是和我一样也有点小困惑,iota 这货到底是啥?

百度翻译给我们的解释是,这货表示"微量",类似英语单词的 little 一样,a little 也表示"一点点".
但是 iota 除了表示一点点之外,好像还拥有自增的能力,这可不是 little 这种量词能够传达的意思.
因此,有可能 iota 并不是原始英语含义,说不定是希腊字母的语言,查询了标准的 24 个希腊字母表以及对应的英语注释.
| 大写 | 小写 | 英文读音 | 国际音标 | 意义 |
|---|---|---|---|---|
| Α | α | alpha | /ˈælfə/ | 角度,系数,角加速度 |
| Β | β | beta | /'beitə/ | 磁通系数,角度,系数 |
| Γ | γ | gamma | /'gæmə/ | 电导系数,角度,比热容比 |
| Δ | δ | delta | /'deltə/ | 变化量,屈光度,一元二次方 |
| Ε | ε | epsilon | /ep'silon/ | 对数之基数,介电常数 |
| Ζ | ζ | zeta | /'zi:tə/ | 系数,方位角,阻抗,相对粘度 |
| Η | η | eta | /'i:tə/ | 迟滞系数,效率 |
| Θ | θ | theta | /'θi:tə/ | 温度,角度 |
| Ι | ι ℩ | iota | /ai'oute/ | 微小,一点 |
| Κ | κ | kappa | /'kæpə/ | 介质常数,绝热指数 |
| ∧ | λ | lambda | /'læmdə/ | 波长,体积,导热系数 |
| Μ | μ | mu | /mju:/ | 磁导系数,微动摩擦系(因)数,流体动力粘度 |
| Ν | ν | nu | /nju:/ | 磁阻系数,流体运动粘度,光子频率 |
| Ξ | ξ | xi | /ksi/ | 随机数,(小)区间内的一个未知特定值 |
| Ο | ο | omicron | /oumaik'rən/ | 高阶无穷小函数 |
| ∏ | π | pi | /pai/ | 圆周率,π(n)表示不大于n的质数个数 |
| Ρ | ρ | rho | /rou/ | 电阻系数,柱坐标和极坐标中的极径,密度 |
| ∑ | σ ς | sigma | /'sigmə/ | 总和,表面密度,跨导,正应力 |
| Τ | τ | tau | /tau/ | 时间常数,切应力 |
| Υ | υ | upsilon | /ju:p'silən/ | 位移 |
| Φ | φ | phi | /fai/ | 磁通,角,透镜焦度,热流量 |
| Χ | χ | chi | /kai/ | 统计学中有卡方(χ2)分布 |
| Ψ | ψ | psi | /psai/ | 角速,介质电通量 |
| Ω | ω | omega | /'oumigə/ | 欧姆,角速度,交流电的电角度 |
希腊字母常常用于物理,化学,生物,科学等学科,作为常量或者变量,不同于一般的英语变量或常量的是,希腊字母表示的变量或常量一般具有特定的语义!
因此,iota 应该是希腊字母 I 的英语表示,该变量或者说常量表示微小,一点的含义.
翻译成自然语言就是,这个符号表示一点点,如果表达改变的含义,那就是在原来基础上多那么一点点,如果表达不改变的含义,应该是只有一点点,仅此而已.

当然,以上均是个人猜测,更加专业的说法还是应该看下 Go 语言如何定义 iota ,按住 Ctrl 键,鼠标悬停在 iota 上可以点击进入源码部分,如下:
// iota is a predeclared identifier representing the untyped integer ordinal
// number of the current const specification in a (usually parenthesized)
// const declaration. It is zero-indexed.
const iota = 0 // Untyped int.
简短翻译:
iota 是预定义标识符,代表当前常量中无符号整型的序号,是以 0 作为索引的.
上述注释看起来晦涩难懂,如果是常量那就就安安静静当做常量,不行吗?怎么从常量定义中还读出了循环变量索引的味道?
为了验证猜想,仍然以最简单的星期转换为例,模拟每一步时的 iota 的值.
const (
// iota = 0,Mon = 1 + 0 = 1,符合输出结果 1,此时 iota = 1,即 iota 自增1
Mon = 1 + iota
// iota = 1,Tue = 1 + iota = 1 + 1 = 2,符合输出结果 2,此时 iota = 2
Tue
// iota = 2,Wed = 1 + iota = 1 + 2 = 3,符合输出结果 3,此时 iota = 3
Wed
Thu
Fri
Sat
Sun
)
// 1 2 3 4 5 6 7
t.Log(Mon, Tue, Wed, Thu, Fri, Sat, Sun)
上述猜想中将 iota 当做常量声明循环中的变量 i,每声明一次,i++,因此仅需要定义循环初始条件和循环自增变量即可完成循环赋值.
const (
Mon = 1 + iota
Tue
Wed
Thu
Fri
Sat
Sun
)
// 1 2 3 4 5 6 7
t.Log(Mon, Tue, Wed, Thu, Fri, Sat, Sun)
var days [7]int
for i := 0; i < len(days); i++ {
days[i] = 1 + i
}
// [1 2 3 4 5 6 7]
t.Log(days)
这样对应是不是觉得 iota 似乎就是循环变量的 i,其中 Mon = 1 + iota 就是循环初始体,Mon~Sun 有限常量就是循环的终止条件,每一个常量就是下一次循环.
如果一个例子不足以验证该猜想的话,那就再来一个!
const (
Readable = 1 << iota
Writing
Executable
)
// 0001 0010 0100 即 1 2 4
t.Log(Readable, Writing, Executable)
var access [3]int
for i := 0; i < len(access); i++ {
access[i] = 1 << uint(i)
}
// [1 2 4]
t.Log(access)
上述两个例子已经初步验证 iota 可能和循环变量 i 具有一定的关联性,还可以进一步接近猜想.
const (
// iota=0 const=1+0=1 iota=0+1=1
first = 1 + iota
// iota=1 const=1+1=2 iota=1+1=2
second
// iota=2 const=2+2=4 iota=2+1=3
third = 2 + iota
// iota=3 const=2+3=5 iota=3+1=4
forth
// iota=4 const=2*4=8 iota=4+1=5
fifth = 2 * iota
// iota=5 const=2*5=10 iota=5+1=6
sixth
// iota=6 const=6 iota=6+1=7
seventh = iota
)
// 1 2 4 5 8 10 6
t.Log(first, second, third, forth, fifth, sixth, seventh)
const currentIota = iota
// 0
t.Log(currentIota)
var rank [7]int
for i := 0; i < len(rank); i++ {
if i < 2 {
rank[i] = 1 + i
} else if i < 4 {
rank[i] = 2 + i
} else if i < 6 {
rank[i] = 2 * i
} else {
rank[i] = i
}
}
// [1 2 3 4 5 6 7]
t.Log(rank)
iota 是一组常量初始化中的循环变量索引,当这一组变量全部初始化完毕后,iota 重新开始计算,因此新的变量 currentIota 的值为 0 而不是 7
因此,iota 常常用作一组有规律常量的初始化背后的原因可能就是循环变量进行赋值,按照这个思路理解前面关于 iota 的例子暂时是没有任何问题的,至于这种理解是否准确,有待继续学习 Go 作进一步验证,一家之言,仅供参考!
1.2.2. 变量和常量的基本小结
- 变量用
var关键字声明,常量用const关键字声明. - 变量声明并赋值的形式比较多,使用时最好统一一种形式,避免风格不统一.
- 变量类型具备自动推断能力,但本质上仍然是强类型,不同类型之间并不会自动转换.
- 一组规律的常量可以用
iota常量进行简化,可以暂时理解为采用循环方式对变量进行赋值,从而转化成常量的初始化. - 变量和常量都具有相似的初始化形式,与其他编程语言不同之处在于一条语句中可以对多个变量进行赋值,一定程度上简化了代码的书写规则.
- 任何定义但未使用的变量或常量都是不允许存在的,既然用不着,为何要声明?!禁止冗余的设计,好坏暂无法评定,既然如何设计,那就遵守吧!
1.3. 与众不同的变量和常量
斐波那契数列是一组无穷的递增数列,形如 1,1,2,3,5,8,13... 这种从第三个数开始,后面的数总是前两个数之和的数列就是斐波那契数列.
如果从第三个数开始考虑,那么前两个数就是斐波那契数列的起始值,以后的数字都符合既定规律,取前两个数字当做变量 a,b 采用循环的方式不断向后推进数列得到指定长度的数列.
func TestFib(t *testing.T) {
var a int = 1
var b int = 1
fmt.Print(a)
for i := 0; i < 6; i++ {
fmt.Print(" ", b)
temp := a
a = b
b = temp + b
}
fmt.Println()
}
虽然上述解法比较清晰明了,但还不够简洁,至少没有用到 Go 语言的特性.实际上,我们还可以做得更好,或者说用 Go 语言的特性来实现更加清晰简单的解法:
func TestFibSimplify(t *testing.T) {
a, b := 0, 1
for i := 0; i < 6; i++ {
fmt.Print(" ", b)
a, b = b, a+b
}
fmt.Println()
}
和第一种解法不同的是,这一次将变量 a 向前移一位,人为制造出虚拟头节点 0,变量 a 的下一个节点 b 指向斐波那契数列的第一个节点 1,随着 a 和 b 相继向后推进,下一个循环中的节点 b 直接符合规定,相比第一种解法缩短了一个节点.
a, b := 0, 1 是循环开始前的初始值,b 是斐波那契数列中的第一个节点,循环进行过程中 a, b = b, a+b 语义非常清楚,节点的 a 变成节点 b,节点 b 是 a+b 的值.
是不是很神奇,这里既没有用到临时变量存储变量 a 的值,也没有发生变量覆盖的情况,直接完成了变量的交换赋值操作.
由此可见, a, b = b, a+b 并不是 a=b 和 b=a+b 的执行结果的累加,而是同时完成的,这一点有些神奇,不知道 Go 是如何实现多个变量同时赋值的操作?
如果有小伙伴知道其中奥妙,还望不吝赐教,大家一起学习进步!
如果你觉得上述操作有点不好理解,那么接下来的操作,相信你一定会很熟悉,那就是两个变量的值进行交换.
func TestExchange(t *testing.T) {
a, b := 1, 2
t.Log(a, b)
a, b = b, a
t.Log(a, b)
temp := a
a = b
b = temp
t.Log(a, b)
}
同样的是,a, b = b, a 多变量同时赋值直接完成了变量的交换,其他编程语言实现类似需求一般都是采用临时变量提前存储变量 a 的值以防止变量覆盖,然而 Go 语言的实现方式竟然和普通人的思考方式一样,不得不说,这一点确实不错!
通过简单的斐波那契数列,引入了变量和常量的基本使用,以及 Go 的源码文件相应规范,希望能够带你入门 Go 语言的基础,了解和其它编程语言有什么不同以及这些不同之处对我们实际编码有什么便捷之处,如果能用熟悉的编程语言实现 Go 语言的设计思想也未曾不是一件有意思的事情.
下面,简单总结下本文涉及到的主要知识点,虽然是变量和常量,但重点并不在如何介绍定义上,而是侧重于特殊之处以及相应的实际应用.
- 源码文件所在的目录和源码文件的所在包没有必然联系,即
package main所在的源码文件并不一定在main目录下,甚至都不一定有main目录.
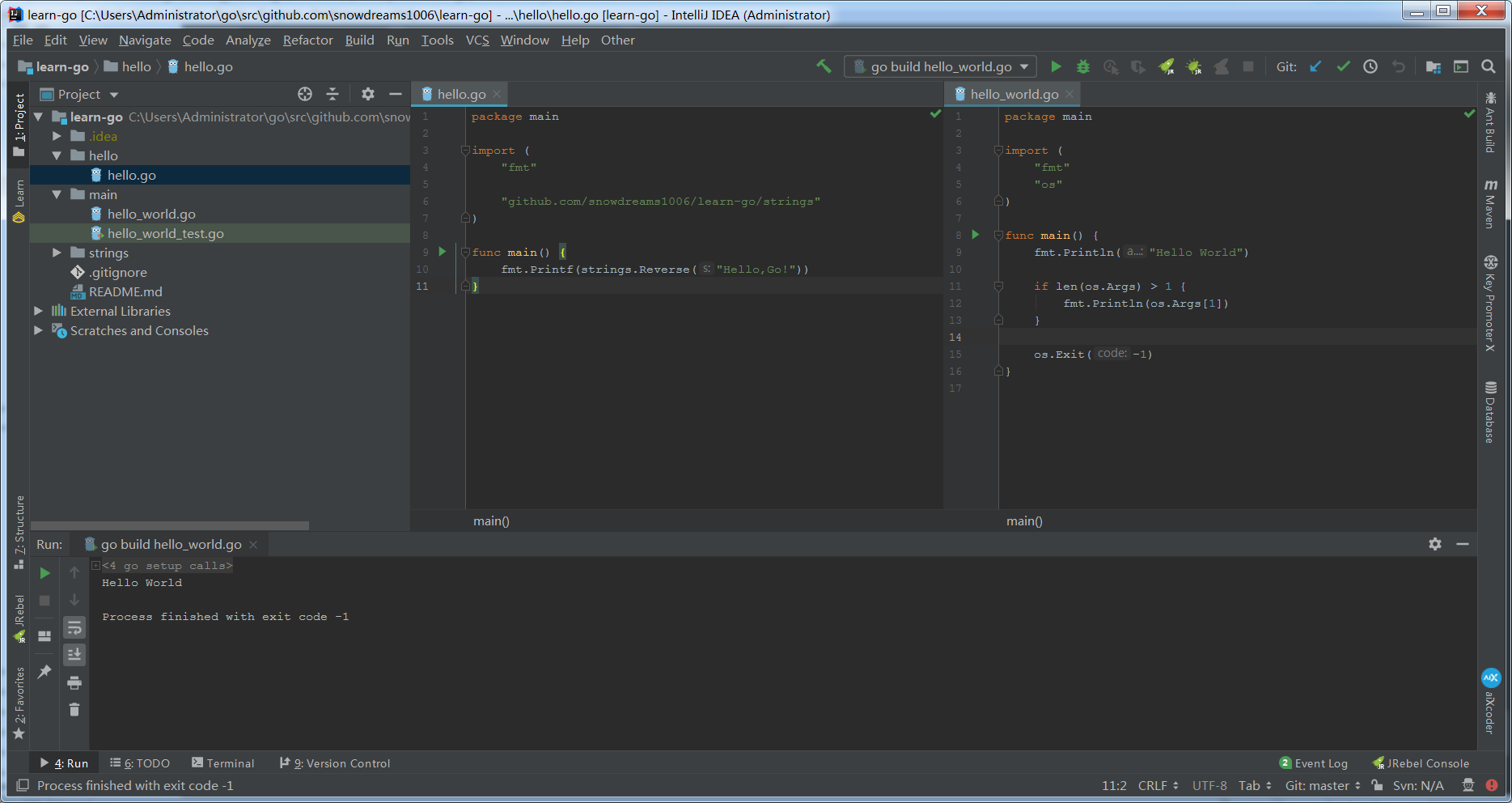
hello.go源码文件位于hello目录下,而hello_word.go位于main目录下,但是他们所在的包都是package main
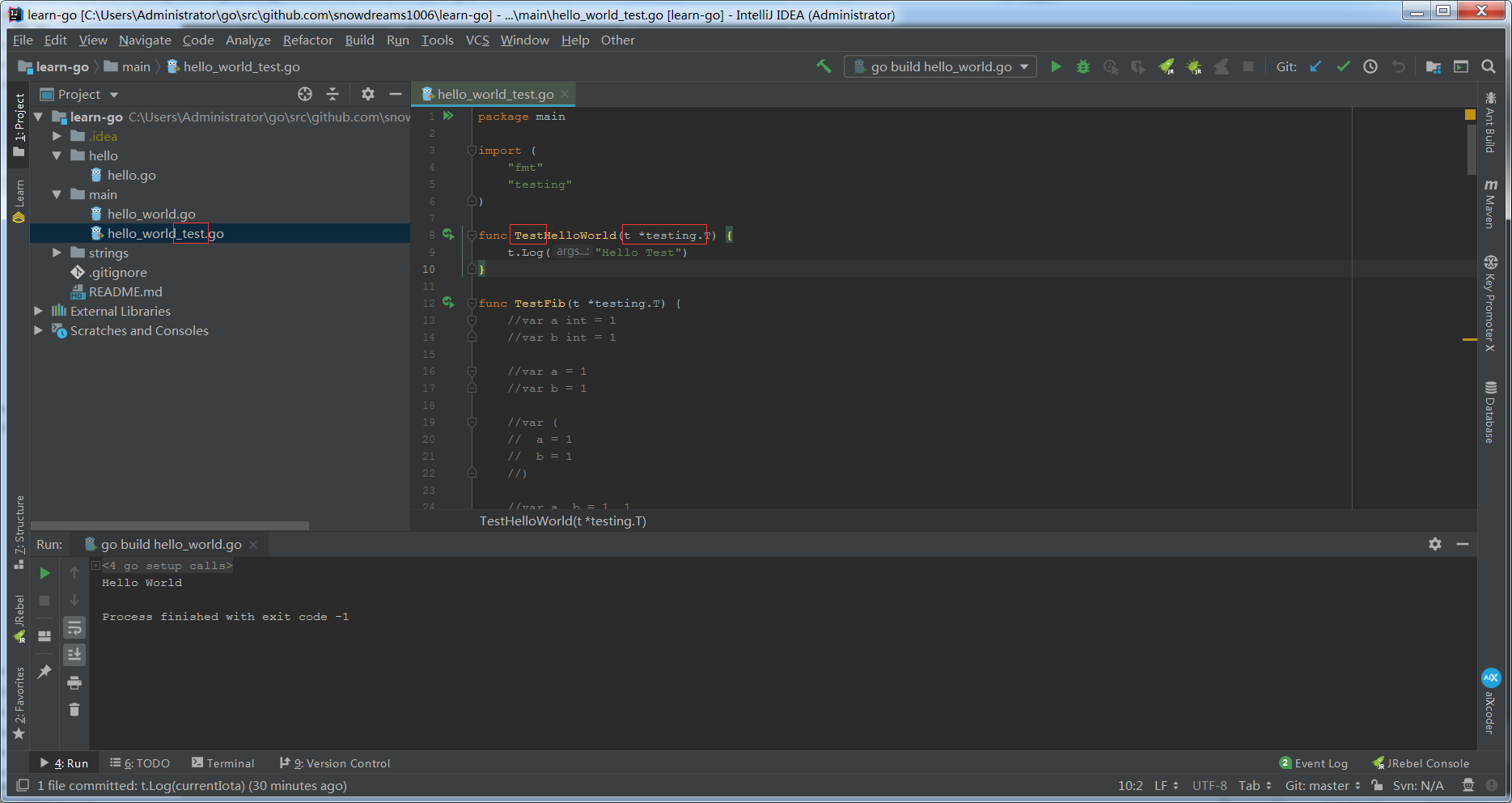
- 源码文件命名暂时不知道有没有什么规则,但测试文件命名一定是
xxx_test,测试方法命名是TestXXX,其中Go天生支持测试框架,不用额外加载第三方类库.
- 声明变量的关键字是
var,声明常量的关键字是const,无论是变量还是常量,均存在好几种声明方式,更是存在自动类型推断更可以进行简化.
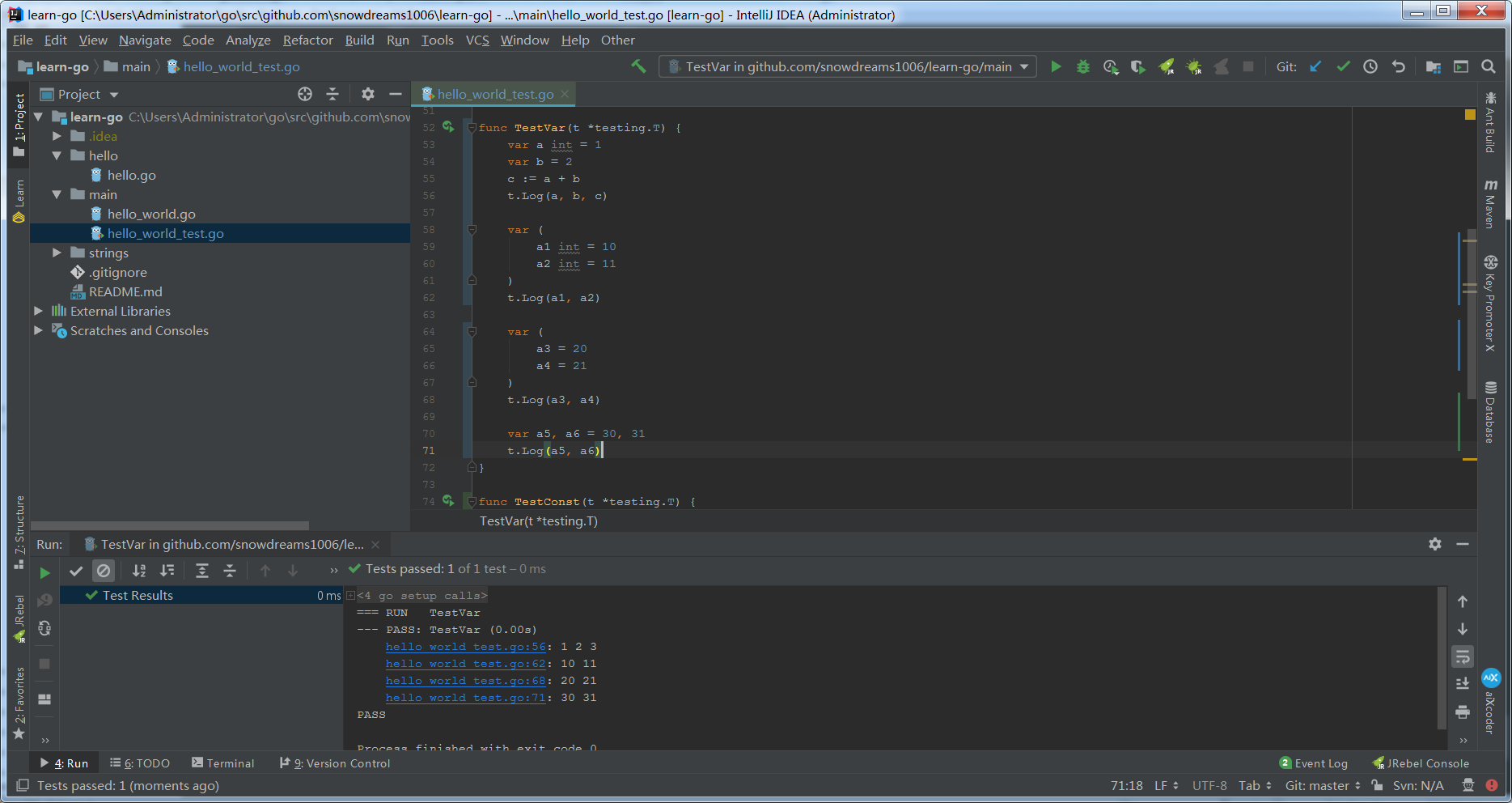
一般而言,实现其它编程语言中的全局变量声明用
var,局部变量声明:=简化形式,其中多个变量可以进行同时赋值.
- 一组特定规律的常量值可以巧用
iota来实现,可以理解为首次使用iota的常量是这组常量规律的第一个,其余的常量按照该规律依次初始化.
Go语言没有枚举类,可以用一组常量值实现枚举,毕竟枚举也是特殊的常量.
本文源码已上传到 https://github.com/snowdreams1006/learn-go 项目,感兴趣的小伙伴可以点击查看,如果文章中有描述不当之处,恳请指出,谢谢你的评论和转发.
作者: 雪之梦技术驿站
链接: https://snowdreams1006.github.io/go/base/var-and-const.html
来源: 雪之梦技术驿站
本文原创发布于「雪之梦技术驿站」,转载请注明出处,谢谢合作!
